Are you using Ennov to store &
manage your submission content?
Combined with the power of DocShifter,
take submission document preparation automation
to the next level.
Generate fully-compliant submission-ready PDFs from your documents
Automatically check & fix Word & PDF files for compliance
Automate report compilation from document collections
Fully automated PDF manipulation
Trigger advanced automation leveraging all Ennov metadata
Do you recognize these challenges?

Your renditions generated in OT Documentum are not submission-ready

You are not able to create consolidated, compliant PDFs from virtual documents

You spend a lot of time / effort to ensure document compliance for submissions
Achieve document compliance in the Ennov platform.
With DocShifter's
powerful document automation capabilities.
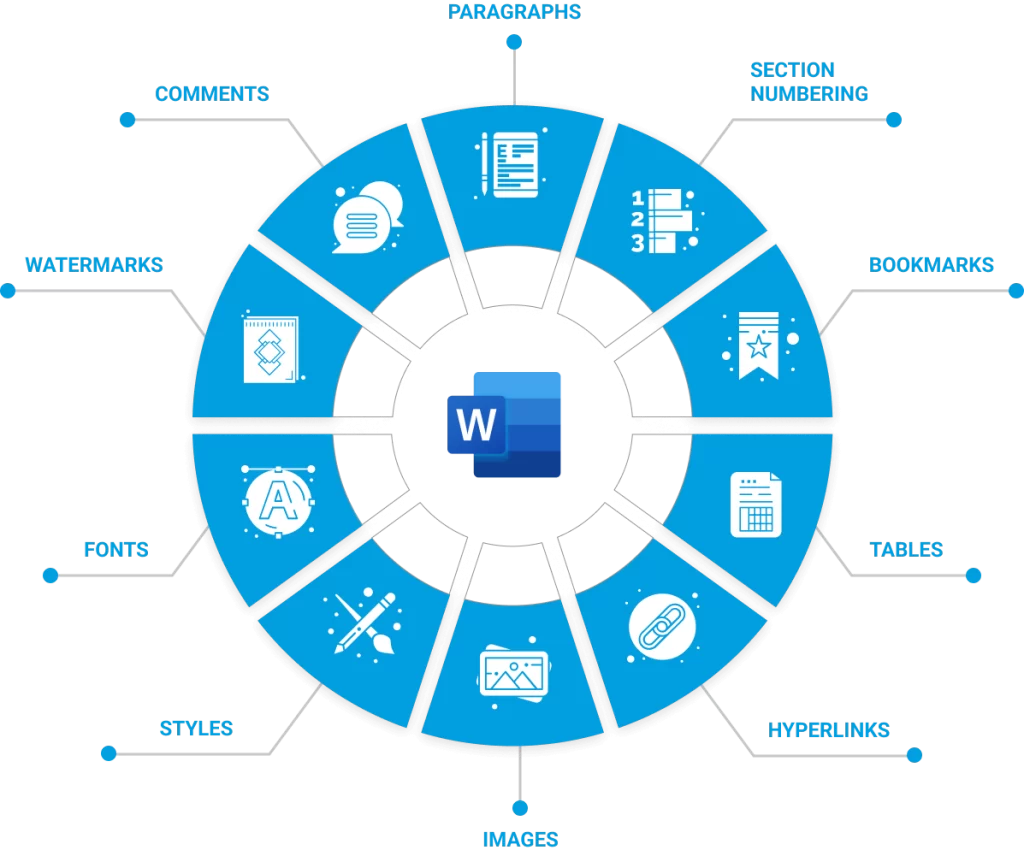
Submission-ready PDF Rendering
Automatically generate navigation-rich, high-quality, auditable and submission-ready PDF documents from the Ennov platform.
- Generate bookmarks from any styles, including your own custom styles
- Ensure hyperlinks are consistently formatted and styled
- Set magnification and zoom level for bookmarks and hyperlinks
- Automatically create bookmarks for PDFs that have no bookmarks (based on text font, size, and more)
- Advanced image handling within documents (dpi, encoding, quality, etc.)
- Advanced image and email format conversions (sizing, orientation, aspect ratio, scaling, and more)
- Advanced Word, Excel, PowerPoint, email, text and image format handling
- Ensure tracked changes convert consistently
- Field code handling to ensure content is up-to-date
- Process or exclude embedded files (including zip, docx, and more)
- Generate bookmarks from any styles, including your own custom styles
- Ensure hyperlinks are consistently formatted and styled
- Set magnification and zoom level for bookmarks and hyperlinks
- Automatically create bookmarks for PDFs that have no bookmarks (based on text font, size, and more)
- Convert from various input formats to PDF or PDF/A
- Select the PDF or PDF/A version of your choice
- Set PDF properties and leverage any DMS metadata
- Flatten PDFs where needed
- Optimize PDF (including for fast web view)
- Ensure PDF viewing preferences are set correctly
- Embed fonts as required (all, subset, nonstandard, and more)
- Automatic font substitutions where fonts are unavailable
- Force specific font substitutions to use available fonts
- Embed attachments
- Fit Excel sheet to a PDF page
- Define the Excel paper size for rendering
- Only render selected sheets in an Excel file to PDF
- And many more
- PDF branding features including watermarks, headers and footers, numbers and many more
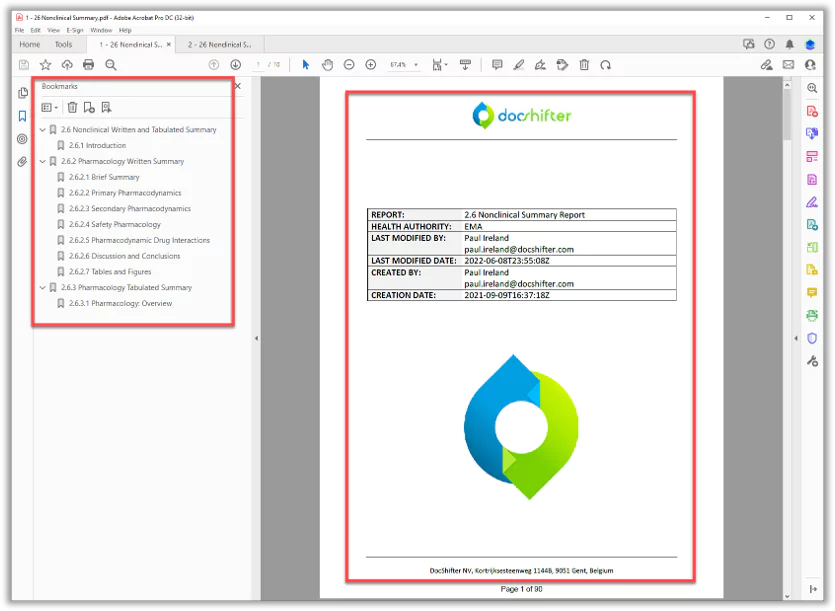
Report Level Publishing
Merge multiple documents from any supported format into one or more compliant PDF report(s).
- Automatically add cover pages to your reports
- Add cover pages at the start and end of reports
- Add cover pages at the start or end of each report volume (where output is more than one PDF file)
- Template designs directly in Microsoft Word
- Generate tables of contents for entire reports
- Generate tables of figures for entire reports
- Handle all content, table and appendices tables
- Use attributes and metadata from your document management system
- Include dynamic titles and visuals in your cover pages, tables of contents, headers & footers, and more
- Add consistent pagination including page and volume numbers, and totals
Automatically check and fix Microsoft Word documents for compliance
Remove the manual workload, reduce costs and secure absolute compliance with DocShifter’s automated Word format fixer. Quality control and quality assurance for Microsoft Word documents has never been this easy.
- Breaks in space paragraphs
- Empty paragraphs
- Highlighted text
- Manual page break
- Unused bookmarks
- Watermarks present
- Images not inline
- Low resolution images
- Incorrectly formatted images
- In-table small font size issues
- Table not fitting to page
- Table header row not repeating
- Table with row breaks across page
- Corrupt style alias
- Instructional style used
- Narrative text formatting issues
- Non-black text
- Blue text not linked
- Cross-reference issues
- External link formatting
- Hyperlinks to external documents
- Internal hyperlink target mismatch
- Internal hyperlink with no target
- Internal reference document(s)
- Web links present
- Numbering issues
- Headings out of sequence
- Headings with white spaces
- Heading/title with break
- Comments present
- Track changes enabled
Have questions about the combination of DocShifter automation in Ennov?

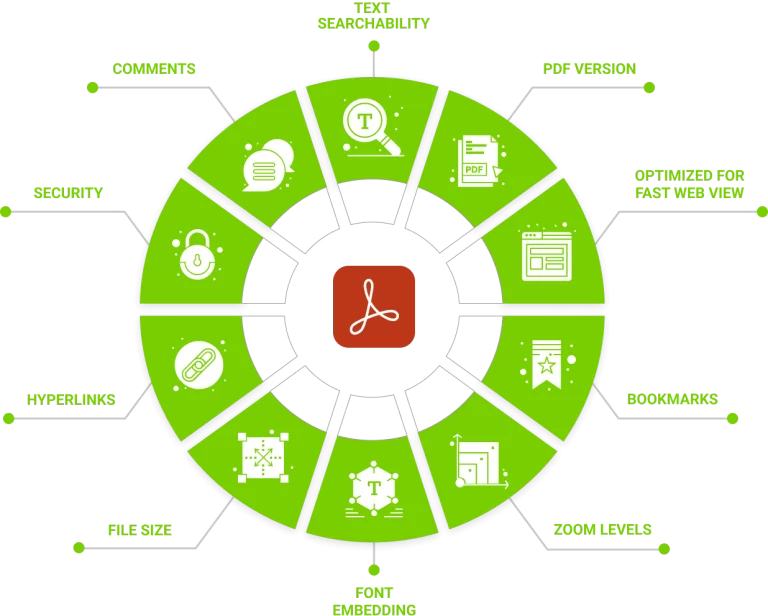
Automatically validate and fix PDFs for compliance
Do you receive PDFs from external stakeholders? Do you want to make sure these PDFs comply with internal and external regulations before they are included in the submission?
- Bookmarks only included to (and open to) the correct level
- Bookmark nesting issues
- Look for broken & no-action bookmarks
- All bookmarks are set to correct zoom level (eg. inherit zoom)
- Check bookmarks exist where necessary
- Ensure bookmarks exist for each ToC entry
- Check first bookmark points to first page
- Check bookmarks point to correct page
- All hyperlinks are the correct colour (e.g. blue)
- No invisible or broken hyperlinks exist
- Relative paths are used for all hyperlinks
- No external links are included
- All hyperlinks are set to correct zoom level (eg. inherit zoom)
- Identify any non-linked blue text
- Check a ToC is included, if needed
- Check hyperlinks point to correct pages
- The PDF file size does not exceed any regulatory limits
- Check no security (passwords or restricted access) is applied
- The PDF version is correct
- The PDF is optimized fo ‘fast web view’
- Check for font and initial view issues
- Check used fonts are embedded correctly
- Check initial page layout and magnification are set correctly
- Page sizes are correct (A4, Letter, etc)
- The initial page orientation is portrait
- There are no blank pages
- Page numbering is sequential
- Ensure headers and first page are not set to draft
- Look for any text remaining in the margins
- The PDF is not empty and contains searchable text
- No track changes exist
- No annotations (of specific types) or comments remain
- No digital signatures are included
Achieve document compliance in Ennov RIM.
With powerful document automation.
Submission-ready PDF rendering for content stored in OpenText Documentum
Create compliant PDFs for one or multiple health authorities simultaneously
Leading pharmaceutical & biotechnology companies use DocShifter to create simultaneous compliant PDF renditions for multiple regions.
Take your submission documents in various formats in OpenText Documentuım, and create FDA, PMDA, EMA compliant PDFs. High quality, navigation-rich, text searchable.
Compliant PDFs. Without any manual work.
DocShifter’s PDF+ offers hundreds of PDF configuration options and is designed to handle the most demanding of health authority technical requirements.
Win valuable time by merging virtual documents into compliant reports.
Without any manual work.
Monitor for status update, metadata or lifecycle in OpenText Documentum
Simply define what content you want to go into the report. DocShifter will monitor triggers in your OpenText Documentum environment, and automate the creation of your report by merging documents together.
Say goodbye to manually adding cover pages, table of content, pagination and many more.
Monitoring the job queue and ssing triggers in OpenText Documentum to automate report generation
When your documents reach a certain lifecycle status, or when a certain document lifecycle is reached, or when a document is checked in OpenText Documentum, the defined DocShifter workflow will kick in to pick up documents and automatically create a report.
You can define routes to handle documents in specific ways. For example, 1 DocShifter workflow can be configured to watch for both clinical and IMPD documents and handle them differently.
Automated Word content preparation for content stored in OpenText Documentum
Automate Word authoring
Reduce the pain of preparing content for regulatory submissions. Allow your teams to focus on the content, and not on the styling. Speed up your regulatory submissions, accelerate time to market.
Check and fix MS Word documents for styling and formatting errors.
Automated checks for your Word documents in OpenText Documentum.
Automatically check for issues with:
- Paragraph
- Tables
- Linking
- Images
- Styles
- Headings
Auto validate PDF documents against internal and external guidelines.
Automatically fix any outstanding issues.
Do my PDFs meet specific requirements?
DocShifter’s PDFValidator automatically validates PDF files against health authority and other technical compliance guidelines, regardless of the original application it was created in. With automated validation, PDFValidator ensures all PDFs included in a regulatory submission are technically compliant. Without exception.
Check for a wide range of issues
Automate PDF content checking and validation for your PDFs stored in OpenText Documentum.
Check and fix issues related with:
- Bookmarks
- PDF properties & security issues
- Page
- Hyperlinks
- Font and initial view
- Annotation and text
What are the recommended system requirements for DocShifter?
DocShifter works with Linux, Windows, Docker/Kubernetes; 32GB RAM, 50GB storage, JAva JRE or JDK, and Visual C++ Redistributable for Visual Studio. Please contact us here to talk to us about more specific details for your environment.
How does DocShifter PDF+ convert Microsoft Excel spreadsheets into PDF?
From scaling content to fit the defined page size, automatically setting the page size based on the content – and even converting each sheet to a single PDF page – there are multiple options available when handling Excel files in DocShifter.
Can we convert signed PDF’s using DS PDF+?
Absolutely. DocShifter can recognize if a PDF file is signed and process it differently from non-signed content. PDfs can be flattened if required, and original signed PDFs can be attached to converted PDF files to retain any of the original signatures.
Does DocShifter software support optical character recognition (OCR)?
DocShifter allows for fully-automated OCR from any file format supported, which includes all image formats listed in a given RFP. The accuracy of results will depend on the quality of the image being processed via OCR, so the required 90% guarantee cannot be achieved without the quality of the content source also being guaranteed.
Where is DocShifter deployed?
DocShifter’s software can be deployed on-premise or in your cloud (AWS/Azure/Google). On Microsoft Windows or Linux. Either directly onto hardware, using VMWare or in a Docker / Kubernetes infrastructure.
We need the conversion functionality for a one-off conversion project, but are not interested in purchasing conversion software. Can you help?
Absolutely. It’s something we have plenty of experience in. Head over to our Document Conversion Services page to find out how DocShifter’s team can handle all of your document conversion project needs.

Check and fix your MS Word documents in OpenText Documentum for styling and formatting issues
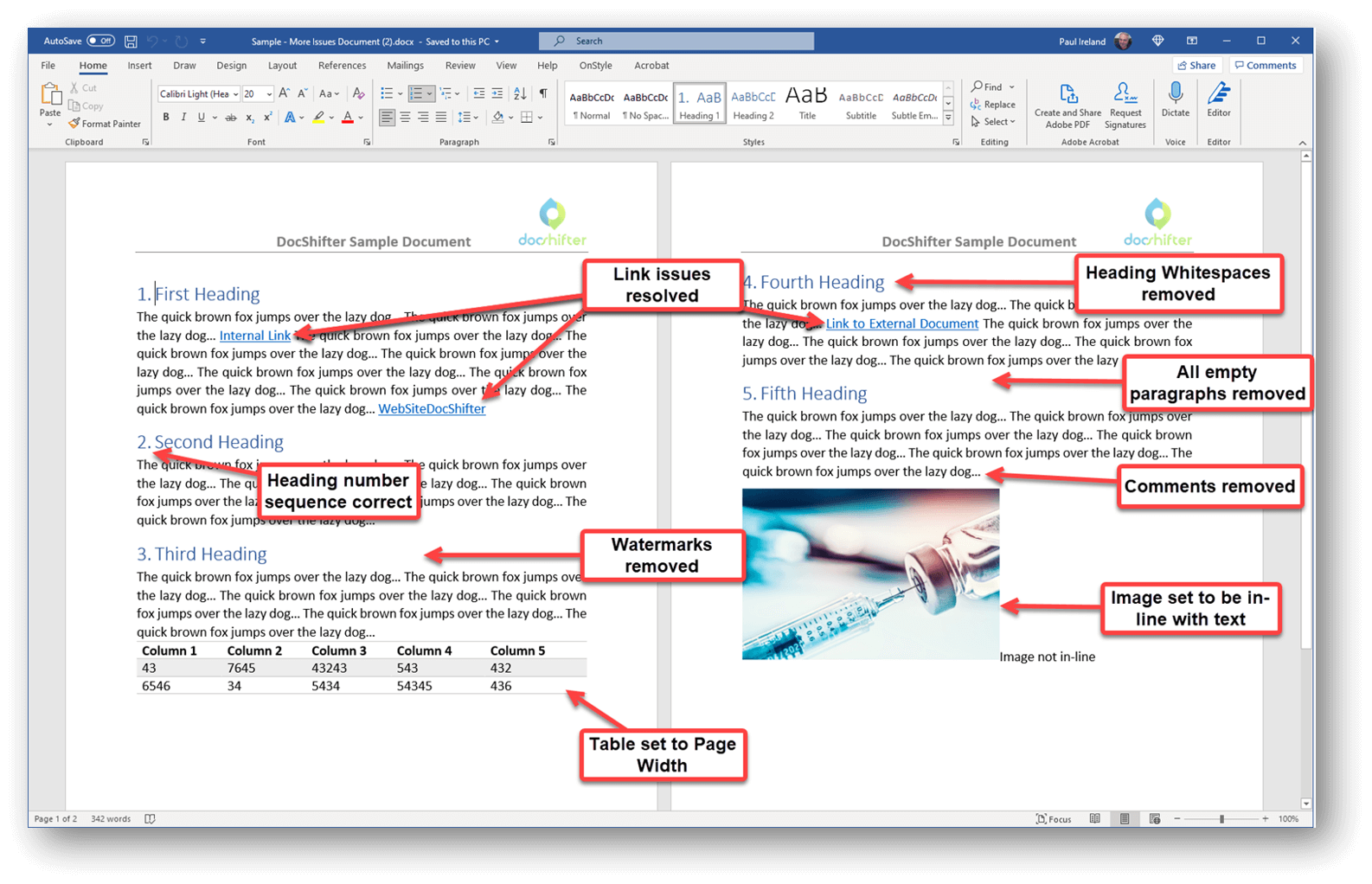
Example of issues automatically fixed by DocShifter DocValidator

Automatically convert virtual documents PDF content into submission-ready PDF with the right PDF specifications
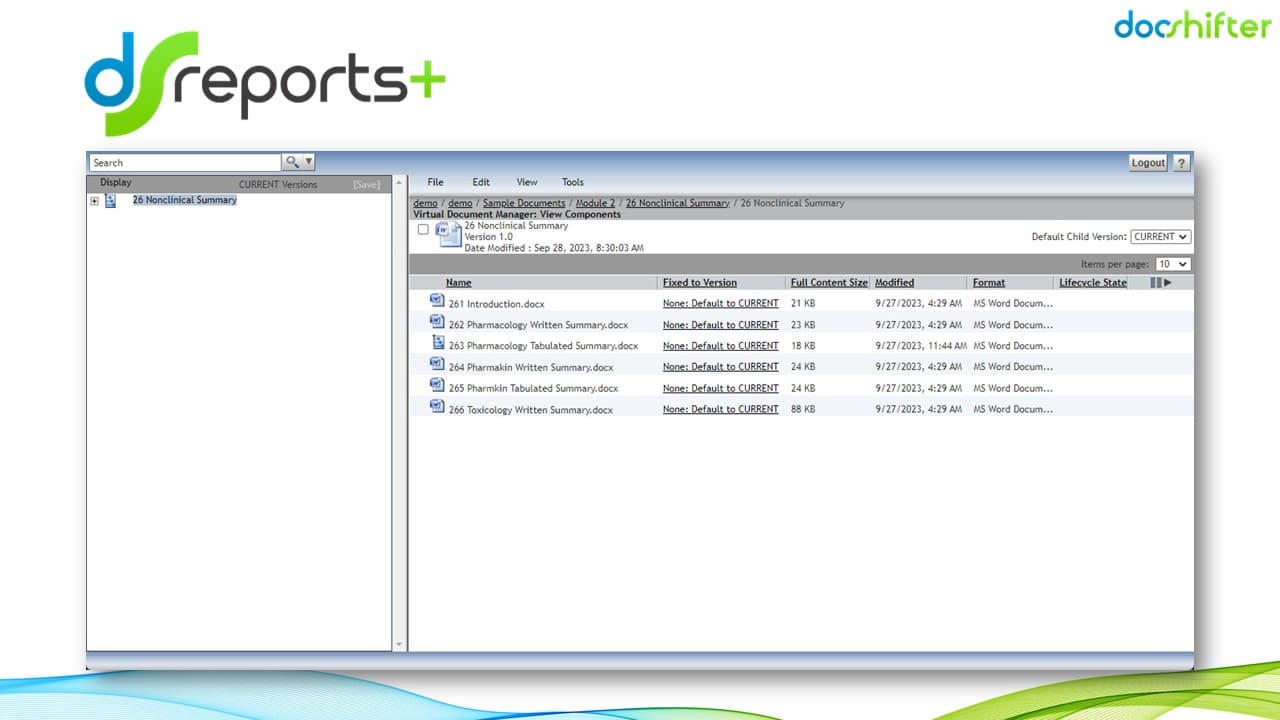
Merge multiple documents into reports. Without any manual work

Example report created in OpenText Documentum by PDFValidator
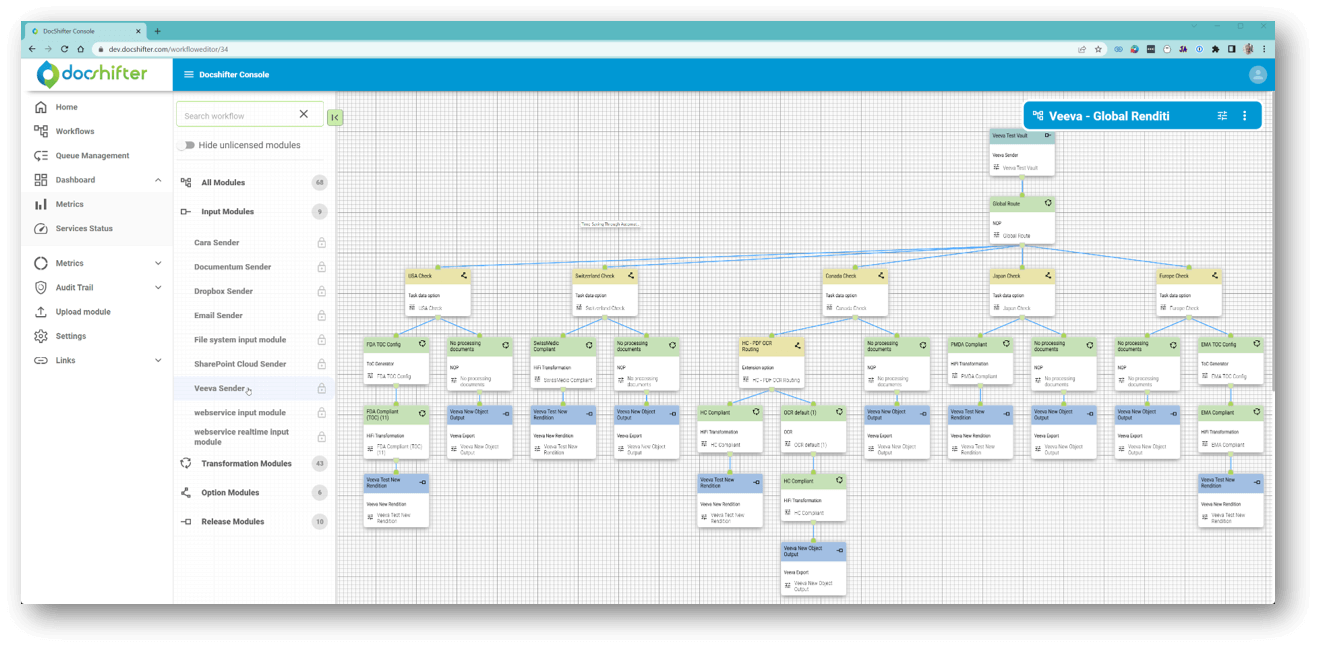
Define different routes and workflows to handle your content in specific ways. Fully automated. Created for and by leading pharmaceutical and life sciences companies.
DocShifter for Life Sciences - FAQ
Does DocShifter also digitize paper documents?
No, digitizing paper documents and paper-to-digital scanning are not services we offer.
Instead, we specialize in digital documents as a starting source, converting to your choice of further digital formats.
Is DocShifter available as a true Software-as-a-Service (SaaS) platform?
No, DocShifter itself does not offer a complete SaaS service today. DocShifter is installed on-premise, in the customer’s cloud, or in his public cloud space. Why is that? Mostly the sheer volume of documents is simply to big to send back and forth over the internet. In addition, privacy is often an important reason for our customers to keep their precious documents close.
If you are interested in a true SaaS platform, running on DocShifter, please leave us a note, we can get you in touch with one of our partners.
Is there any data exchange with third-party services?
No data is exchanged between DocShifter and any other third-party entity. We value the privacy of your documents.
Where is DocShifter installed?
DocShifter can be installed:
- On premise in your own data centre.
- In your private/hybrid or public cloud.
- In Docker containers, orchestrated by Kubernetes.
- On either Windows or Linux. We realize you have a preference.
We used to lose data during conversions. How do you handle it?
DocShifter has been designed to work in regulated industries where extremely high-quality and high- fidelity results are expected. All formatting and content will be included in the results. Some configuration will be required to ensure the results are as required, and it is important to ensure that any fonts used are available (otherwise formatting may change based on the font substitutions required when a font is not installed).
In the specific case of Excel and OpenOffice Calc files, DocShifter has a number of options available to ensure any hidden information or wide sheets are formatted appropriately in the results.
DocShifter Insights (metrics and reports) provides clear visibility into the number of incoming conversion requests and the number of successful and unsuccessful results. This information can be filtered and viewed in a number of different ways. Both tabular and graphically.
How does DocShifter handle confidentiality & security?
We consider confidentiality and security to be a strategic priority within our software. The underlying software dynamics used to convert any document within DocShifter’s environment do not store any data or documents during conversion.
As conversion takes place within your hardware and/or infrastructure, DocShifter has no access to the contents of your documents. We value your privacy and have built DocShifter’s entire suite of solutions to be safe, secure and entirely confidential.
How many DocShifter Servers do I need?
A few factors can help us estimate this for you:
– Number of documents that need to be converted per day, week, etc.
– How quickly you need to receive the results.
– What repositories you are using.
– Intended infrastructure for our servers and the content (on premise, in the cloud, etc.).
– The type of content that needs to be converted.
– Whether high-fidelity / compliant conversion is necessary.
– Do you need High-Availability.
– Is a disaster recovery environment needed.
– How many different non-production environments do you use (test, development, staging, validation, training, etc.)
Please use the form above to begin these discussions.
How does DocShifter's software handle transformation errors?
A number of methods are available for tracking processing errors in DocShifter.
If a job was submitted via web services, any errors or warnings will be returned via the response message for immediate action. Different HTTP status codes are returned depending on the type of issue.
Notifications can also be configured to send alerts via email, SNMP, Webhook or to another database. These can be configured specifically for each workflow created, and different actions deployed, depending on whether it’s a ‘fatal’ or ‘warning’ error.
Error logs feature in the Administration Console for any jobs that have failed, while detailed job logs are also available to provide further detail on the cause of any issue.
Where appropriate, DocShifter’s software will attempt to retry an incomplete job, dependent on the error in question.
Does DocShifter support RESTful API?
Yes. DocShifter fully exposes its functionality via a standard RESTful API.
Does DocShifter software support optical character recognition (OCR)?
DocShifter allows for fully-automated OCR from any file format supported, which includes all image formats listed in a given RFP. The accuracy of results will depend on the quality of the image being processed via OCR, so the required 90% guarantee cannot be achieved without the quality of the content source also being guaranteed.
For more information, please visit our DS OCR software solution page.

Are you looking for ways to further automate and simplify the way you prepare content for submissions in OpenText Documentum?
Everything you need to know is explained in a 30 minute session.

What are the challenges and limitations of PDF manipulation for compliance in life sciences?
What role does automation play?
